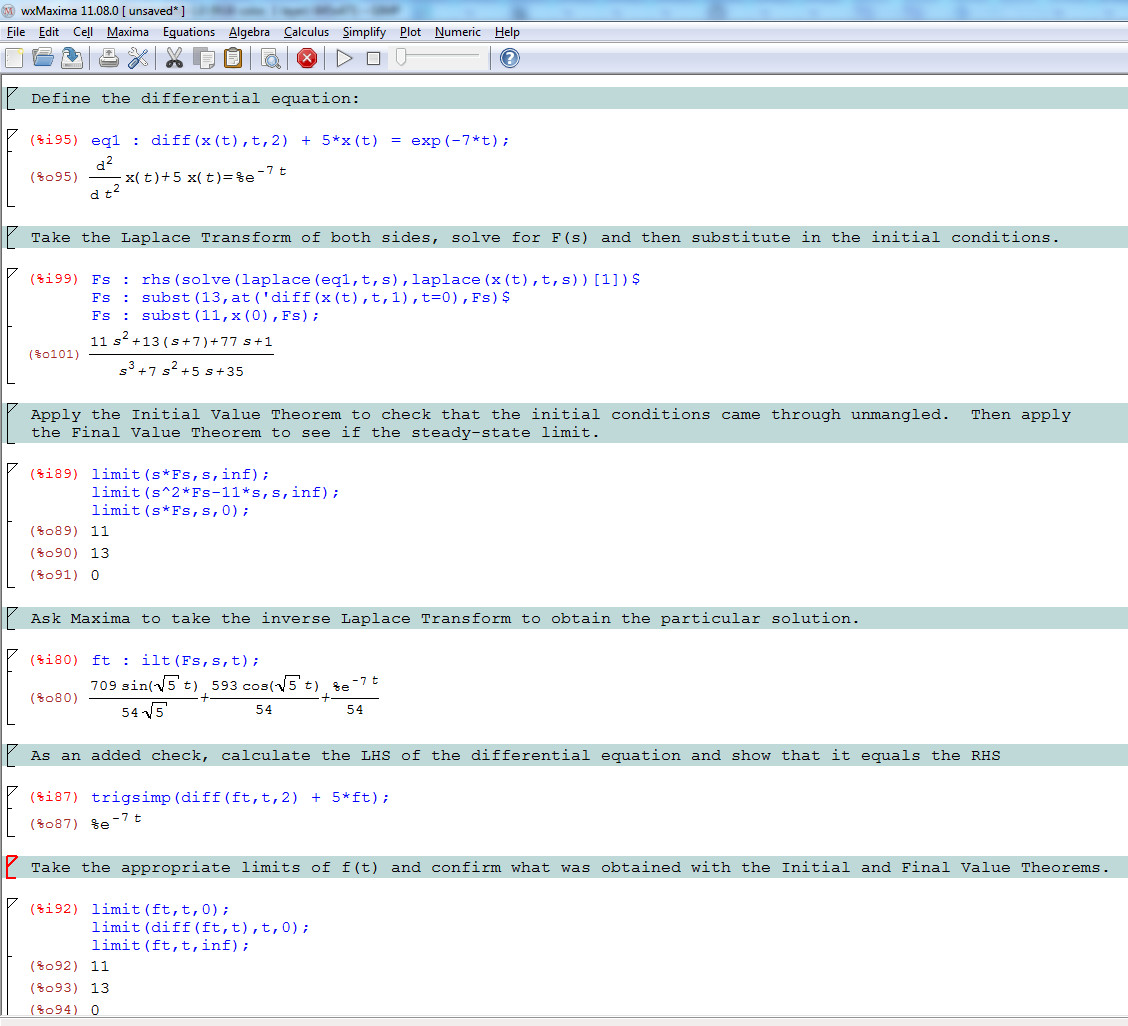
Laplace Transforms – Part 4: Convolution
One of the most peculiar things about the Laplace Transform, specifically, and the integral transforms, in general, is the very nonintuitive behavior that results when performing either the forward or inverse transform on the product of two functions. Up to this point, only very special cases have been covered – cases where the results of the product could be determined easily from the definition of the transform itself (e.g. $${\mathcal L}[t f(t)]$$) or cases where the product of two transforms $$G(s)F(s)$$ resulted in a trivial inverse due to some property of the Laplace Transform that allowed for clever manipulation.
Unfortunately, cleverness has a limit. So this week’s column will be looking at the general theory of the transform/inverse-transform of the product of two functions. This leads directly to the convolution integrals.
The first thing to look at is the case where the product of a set of Laplace Transforms fail to inspire cleverness on our part. This situation can easily arise when solving a differential equation such as
\[ x”(t) + \omega^2 x(t) = f(t), \; \; x(0) = 0, \; x'(0) = 0 \; ,\]
which is the driven simple harmonic oscillator with homogenous initial conditions.
Application of the Laplace transform leads to
\[ X(s) = \frac{F(s)}{s^2 + \omega^2} \]
as the solution that we wish to find by the inverse Laplace Transform, where $$F(s) = {\mathcal L}[f(t)]$$.
For certain forms of $$F(s)$$ (usually simple ones) the inverse Laplace Transform can be done using the properties already established. But clearly, an arbitrary form requires a little something more.
The little bit more comes in the form of the convolution $$f*g$$, defined as
\[ (f*g)(t) = \int_{0}^{t} d\tau \, f(t-\tau) g(\tau) \; .\]
The convolution has exactly the same form as the kernel integration that arises in the study of the Green’s function and has been dealt with in detail in other entries of this blog.
The reason the convolution is useful can be seen if we examine its Laplace Transform
\[ {\mathcal L}[(f*g)(t)] = \int_0^{\infty} dt \, (f*g)(t) e^{-st} = \int_0^{\infty} dt \, \int_0^t d\tau \, f(t-\tau) g(\tau) e^{-st} \; .\]
The inner integral can have the same limits of integration as the outer one if we introduce the Heaviside step function
\[ H(x) = \left\{ \begin{array}{l} 0 \; \; x<0 \\ 1 \; \; x \geq 0 \end{array} \right. \; \] to get \[ {\mathcal L}[(f*g)(t)] = \int_0^{\infty} dt \int_0^{\infty} d\tau \, f(t-\tau) g(\tau) H(t-\tau) e^{-st} \; . \] Next switch the order of integration \[ {\mathcal L}[(f*g)(t)] = \int_0^{\infty} d\tau \, g(\tau) \int_0^{\infty} dt f(t-\tau) H(t-\tau) e^{-st} \; \] and then substitute $$\lambda = t – \tau$$ in the inner integral (realizing that $$\tau$$ is regarded as a parameter) to get \[ {\mathcal L}[(f*g)(t)] = \int_0^{\infty} d\tau \, g(\tau) \int_0^{\infty} d\lambda f(\lambda) H(\lambda) e^{-s(\lambda+\tau)} \; .\] Separate the exponential into two pieces; the first solely involving $$\tau$$ and the second solely involving $$\lambda$$ and bring the last factor out of the inner integral to get \[ {\mathcal L}[(f*g)(t)] = \int_0^{\infty} d\tau \, g(\tau) e^{-s\tau} \int_0^{\infty} d\lambda f(\lambda) H(\lambda) e^{-s\lambda} \; .\] The final two steps are, first, to realize that the $$H(\lambda)$$ term in the inner integral is always $$1$$ and therefore can be dropped and, second, to recognize that each integral is a Laplace Transform. Finally, we arrive at \[ {\mathcal L}[(f*g)(t)] = G(s) F(s) \; .\] At first glance, it may seem that there is a problem with the above relation. Clearly the order of the products on the right-hand side doesn’t matter $$G(s)F(s) = F(s)G(s)$$. In contrast, the left-hand side doesn’t appear to support commutivity of $$f$$ and $$g$$. However, appearances are deceiving, and it is a short proof to show that all is well. Start with the first form of the equation \[ (f*g)(t) = \int_{0}^{t} d \tau \, f(t-\tau) g(\tau) \] and make the substitution $$t-\tau = u$$ (which implies $$d\tau = -du$$) to transform the right-hand side to \[ (f*g)(t) = \int_{t}^{0} (-du) \, f(u) g(t-u) = \int_{0}^{t} du \, g(t-u) f(u) = (g*f)(t) \; .\] Returning to the original differential equation we started to solve, we find that \[ x(t) = \int_0^t \frac{sin(\omega(t-\tau))}{\omega} f(t) \; , \] which is exactly the expected result based on the Green’s function method. Some other interesting properties of the convolution operator is that it is distributive \[ f*(g+h) = f*g + f*h \] and that it is associative \[ (f*g)*h = f*(g*h) \; .\]
Both of these are easy to prove as well. For the first relation
\[ f*(g+h) = \int_0^t d\tau \, f(t-\tau) \left[ g(\tau) + h(\tau) \right] \\ = \int_0^t d\tau \, f(t-\tau) g(\tau) + \int_0^t \, f(t-\tau) h(\tau) = f*g + f*h \; .\]
For the second relation, things are a bit harder. And we’ll take it on faith for now. Having disposed of the forward transform theory in fine order, it is natural to ask about the inverse transform. Here the work is much simpler. There is an analogous expression that states \[ f(t) g(t) = {\mathcal L}^{-1}[ F(s) * G(s) ] \] which not particularly useful but follows just from the simple changing of the identity of the symbols in the analysis above. Finally, one might ask about the Laplace Transform of the product of two arbitrary (but transformable) functions $$f(t) g(t)$$. Here the theory is not so attractive. The transform is given abstractly as
\[ {\mathcal L}[f(t) g(t)] = \frac{1}{2 \pi i} \int_{c-i\infty}^{c+i\infty} \, dp G(s-p) F(p) \\ = \frac{1}{2 \pi i} \int_{c-i\infty}^{c+i\infty} \, dp F(s-p) G(p) \; ,\]
where the real constant $$c$$ is the largest of the abcissa of convergence of $$f(t)$$ and $$g(t)$$. This form is really dreadful and it demonstrates that there is no free lunch anywhere. The transform approach may make certain computations easier but other things are more complex. There are always trade-offs. To see how this comes miserable state-of-affairs about start with the basic definition of the Laplace Transform of the product \[ {\mathcal L}[f(t) g(t)] = \int_0^\infty dt \, f(t) g(t) e^{-st} \; .\] Now assume that both $$f(t)$$ and $$g(t)$$ individually have Laplace transforms so that the inverses \[ f(t) = \frac{1}{2 \pi i} \int_{c_f – i \infty}^{c_f + i \infty} ds \, F(s) e^{st}, \;\; \mbox{for} \; t > 0 \]
and
\[ g(t) = \frac{1}{2 \pi i} \int_{c_g – i \infty}^{c_g + i \infty} ds \, G(s) e^{st}, \;\; \mbox{for} \; t > 0 \]
exist and that $$c_f$$ and $$c_g$$ are the abcissa of convergence associated with the functional form of $$f(t)$$ and $$g(t)$$, respectively.
First substitute the inverse expression for $$f(t)$$ into the basic definition to get
\[ {\mathcal L}[f(t) g(t)] = \int_0^\infty dt \, \left\{ \frac{1}{2 \pi i} \int_{c_f – i \infty}^{c_f + i \infty} dp \, F(p) e^{pt} \right\} g(t) e^{-st} \; .\]
Since the integrals are assumed to be convergent, trading the order of integration is allowed, giving
\[ {\mathcal L}[f(t) g(t)] = \frac{1}{2 \pi i} \int_{c_f – i \infty}^{c_f + i \infty} dp \, F(p) \int_0^\infty dt \, e^{-(s-p)t} g(t) \; .\]
The inner integral can be simplified to
\[ \int_0^\infty dt \, e^{-(s-p)t} g(t) = G(s-p) \; \]
and so we arrive at
\[ {\mathcal L}[f(t) g(t)] = \frac{1}{2 \pi i} \int_{c_f – i \infty}^{c_f + i \infty} dp \, F(p) G(s-p) \; .\]
In a similar fashion (switching the order in which $$f(t)$$ and $$g(t)$$ are handled), we also get the analogous expression with the roles of $$F$$ and $$G$$ reversed.
Next week, I’ll be looking at solving systems of equations using the Laplace Transform, which will be a prelude to a brief dip into modern control theory.